
一(yī)、前言
基于大(dà)數據和機器學習的Web異常參數檢測系統Demo實現。如何在網絡安全領域利用數據科學解決安全問題一(yī)直是一(yī)個火(huǒ)熱的話(huà)題,讨論算法和實現的文章也不少。前段時間看到楚安的文章《數據科學在Web威脅感知(zhī)中(zhōng)的應用》,其中(zhōng)提到如何用隐馬爾可夫模型(HMM)建立web參數模型,檢測注入類的web攻擊。獲益匪淺,遂嘗試用python實現該算法,并嘗試在大(dà)數據環境下(xià)的部署應用。
二、算法一(yī)般過程
隐馬爾可夫模型是一(yī)個統計模型,可以利用這個模型解決三類基本問題:
Ø 學習問題:給定觀察序列,學習出模型參數
Ø 評估問題:已知(zhī)模型參數,評估出觀察序列出現在這個模型下(xià)的概率
Ø 解碼問題:已知(zhī)模型參數和給出的觀察序列,求出可能性最大(dà)的隐藏狀态序列
這裏我(wǒ)們是要解決前兩類問題,使用白(bái)樣本數據學習出模型和參數基線,計算檢測數據在該模型下(xià)出現的可能性,如果得分(fēn)低于基線就可以認爲這個參數異常,産出告警。算法可分(fēn)爲訓練過程和檢測過程,算法本身我(wǒ)這裏不在細說(可參見前言中(zhōng)的文章或兜哥的文章),這裏重點講一(yī)下(xià)參數的抽取和泛化。
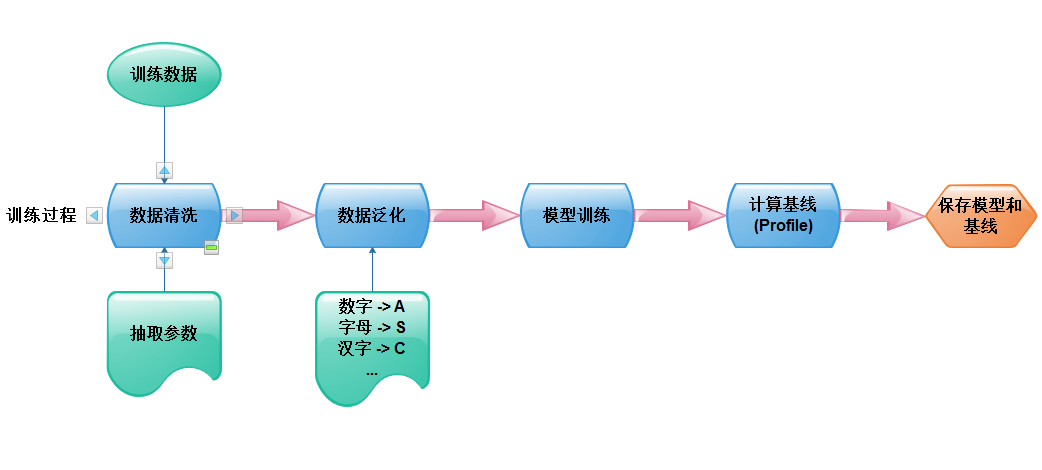
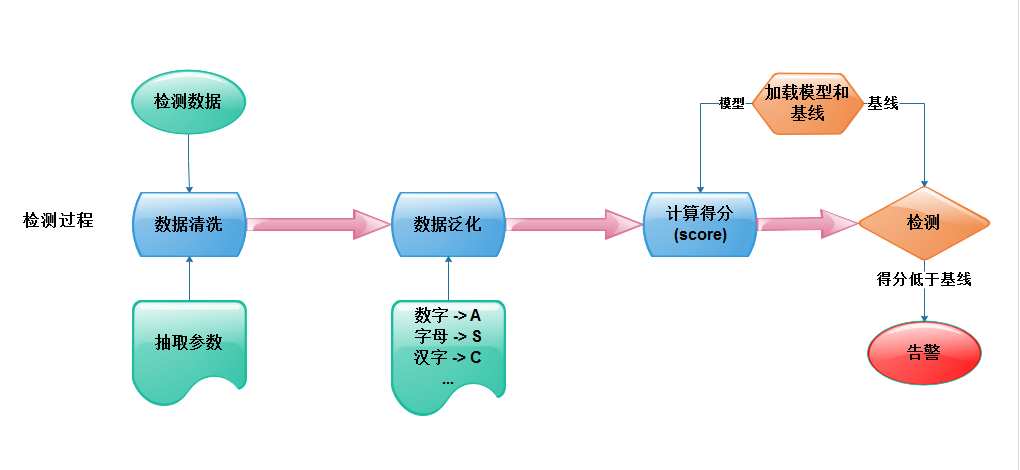
參數的抽取
對http請求數據進行拆解,提取如下(xià)參數,這部分(fēn)的難點在于如何正确的識别編碼方式并解碼:
Ø GET、POST、Cookie請求參數
Ø GET、POST、Cookie參數名本身
Ø 請求的URL路徑
Ø http請求頭,如Content_type、Content-Length(對應strust2-045)
參數泛化
需要将參數值泛化爲規律性的觀測經驗,并取字符的unicode數值作爲觀察序列,泛化的方法如下(xià):
Ø 大(dà)小(xiǎo)寫英文字母泛化爲”A”,對應的unicode數值爲65
Ø 數字泛化爲”N”,對應的unicode數值爲78
Ø 中(zhōng)文或中(zhōng)文字符泛化爲“C”,對應的unicode數值爲67
Ø 特殊字符和其他字符集的編碼不作泛化,直接取unicode數值
Ø 參數值爲空的取0
三、系統架構
在訓練過程中(zhōng)要使用盡可能多的曆史數據進行訓練,這顯然是一(yī)個批(batch)計算過程;在檢測過程中(zhōng)我(wǒ)們希望能夠實時的檢測數據,及時的發現攻擊,這是一(yī)個流(streaming)計算過程。典型的批+流式框架如Cisco的Opensoc使用開(kāi)源大(dà)數據架構,kafka作爲消息總線,Storm進行實時計算,Hadoop存儲數據和批量計算。但是這樣的架構有一(yī)個缺點,我(wǒ)們需要維護Storm和MapReduce兩套不同的代碼。考慮到學習成本,使用Spark作爲統一(yī)的數據處理引擎,即可以實現批處理,也可以使用spark streaming實現近實時的計算。
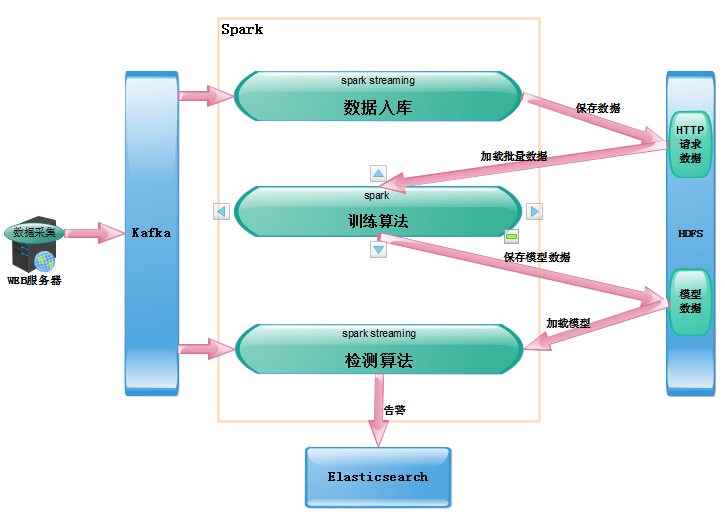
系統架構如上圖,需要在spark上運行三個任務,sparkstreaming将kafka中(zhōng)的數據實時的存入hdfs;訓練算法定期加載批量數據進行模型訓練,并将模型參數保存到Hdfs;檢測算法加載模型,檢測實時數據,并将告警保存到ES。
四、Spark簡介
Apache Spark是一(yī)個快速通用的大(dà)數據計算框架,由Scala語言實現,同時提供Java、python、R語言的API接口。相比于Hadoop的Mapreduce,Spark可以實現在内存中(zhōng)計算,具有更高的計算速度,并且spark streaming提供流數據計算框架,以類似批處理的方式處理流數據。
RDD
RDD是Spark中(zhōng)抽象的數據結構類型,是一(yī)個彈性分(fēn)布式數據集,數據在Spark中(zhōng)被表示爲RDD。RDD提供豐富的API接口,實現對數據的操作,如map、flatmap、reduce、filter、groupby等等。
DStream
DStream(離(lí)散數據流)是Spark Streaming中(zhōng)的數據結構類型,它是由特定時間間隔内的數據RDD構成,可以實現與RDD的互操作,Dstream也提供與RDD類似的API接口。
DataFrame
DataFrame是spark中(zhōng)結構化的數據集,類似于數據庫的表,可以理解爲内存中(zhōng)的分(fēn)布式表,提供了豐富的類SQL操作接口。
五、數據采集與存儲
獲取http請求數據通常有兩種方式,第一(yī)種從web應用中(zhōng)采集日志(zhì),使用logstash從日志(zhì)文件中(zhōng)提取日志(zhì)并泛化,寫入Kafka(可參見兜哥文章);第二種可以從網絡流量中(zhōng)抓包提取http信息。我(wǒ)這裏使用第二種,用python結合Tcpflow采集http數據,在數據量不大(dà)的情況下(xià)可穩定運行。
數據采集
與Tcpdump以包單位保存數據不同,Tcpflow是以流爲單位保存數據内容,分(fēn)析http數據使用tcpflow會更便捷。Tcpflow在linux下(xià)可以監控網卡流量,将tcp流保存到文件中(zhōng),因此可以用python的pyinotify模塊監控流文件,當流文件寫入結束後提取http數據,寫入Kafka,Python實現的過程如下(xià)圖。
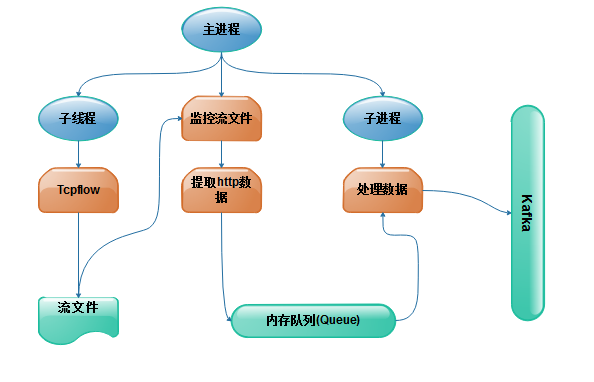
核心代碼:
#子進程,處理數據到kafka
queue = Queue()
threadKafka=Process(target=processKafka,args=(queue,options.kafka,options.topic))threadKafka.start()
#子線程,開(kāi)啓并監控TCPFLOW
tempDir=tempfile.mkdtemp()
threadPacp=threading.Thread(target=processPcap,args=(tempDir,tcpFlowPath,tcpflow_args))
threadPacp.start()
#主進程,監控文件并生(shēng)成數據wm=pyinotify.WatchManager()
wm.add_watch(tempDir,pyinotify.ALL_EVENTS)
eventHandler=MonitorFlow(queue)
notifier=pyinotify.Notifier(wm,eventHandler)
notifier.loop()
數據存儲
開(kāi)啓一(yī)個SparkStreaming任務,從kafka消費(fèi)數據寫入Hdfs,Dstream的python API沒有好的入庫接口,需要将Dstream的RDD轉成DataFrame進行保存,保存爲json文件。
核心代碼:
topic = {in_topic: in_topic_partitions}
#從kafka獲取數據生(shēng)成Dstream
dstream = KafkaUtils.createStream(ssc, zookeeper,app_conf["app_name"], topic)
dstream = dstream.map(lambda record: json.loads(record[1]))
dstream.foreachRDD(lambda rdd: self.save(rdd))
#将RDD轉成DataFrame存入Hdfs
def save(self, rdd):
if rdd.take(1):
df = sqlcontext.createDataFrame(rdd)
df.write.json(app_conf["savedir"], mode="append")
else:
pass
六、算法實現
抽取器(Extractor)
抽取器實現原始數據的參數提取和數據泛化,傳入一(yī)條json格式的http請求數據,可以返回所有參數的id、參數類型、參數名、參數的觀察狀态序列。
代碼示例:
class Extractor(object):
def __init__(self,data):
self.parameter={}
self.data=data
self.uri = urllib.unquote(data["uri"].encode("utf-8"))
self.path = decode(get_path(self.uri))
self.payload = get_payload(self.uri).strip("?")
self.get_parameter()
#提取post參數
def post(self):
post_data=urllib.unquote(urllib.unquote(self.data["data"]))
content_t=self.data["content_type"]
#提取urlencode編碼的參數
def ex_urlencoded(post_data):
for p in post_data.split("&"):
p_list = p.split("=")
p_name = p_list[0]
if len(p_list) > 1:
p_value = reduce(operator.add, p_list[1:])
#取md5作爲參數id
p_id = get_md5(self.data["host"] + self.path + decode(p_name) + self.data["method"])
p_state = self.get_Ostate(p_value)
p_type = "post"
yield (p_id, p_state, p_type, p_name)
#提取json格式的參數
def ex_json(post_data):
post_data=json.loads(post_data)
for p_name,p_value in post_data.items():
p_id = get_md5(self.data["host"] + self.path + decode(p_name) + self.data["method"])
p_state=self.get_Ostate(str(p_value))
p_type="post"
yield (p_id, p_state, p_type, p_name)
訓練器(Trainer)
訓練器完成對參數的訓練,傳入參數的所有觀察序列,返回訓練好的模型和profile,HMM模型使用python下(xià)的hmmlearn模塊,profile取觀察序列的最小(xiǎo)得分(fēn)。
核心代碼:
class Trainer(object):
def __init__(self,data):
self.p_id=data["p_id"]
self.p_state=data["p_states"]
def train(self):
Hstate_num=range(len(self.p_state))
Ostate_num=range(len(self.p_state))
Ostate = []
for (index,value) in enumerate(self.p_state):
Ostate+=value #觀察狀态序列
Hstate_num[index]=len(set(np.array(value).reshape(1,len(value))[0]))
Ostate_num[index]=len(value)
self.Ostate=Ostate
self.Hstate_num=Hstate_num
self.n=int(round(np.array(Hstate_num).mean()))#隐藏狀态數
model = GaussianHMM(n_components=self.n, n_iter=1000, init_params="mcs",covariance_type="full")
model.fit(np.array(Ostate),lengths=Ostate_num)
#計算基線
def get_profile(self):
scores=np.array(range(len(self.p_state)),dtype="float64")
for (index,value) in enumerate(self.p_state):
scores[index]=self.model.score(value)
self.profile=float(scores.min())
self.scores=scores
訓練任務
Spark訓練任務抽取所有http請求數據的參數,并按照參數ID分(fēn)組,分(fēn)别進行訓練,将訓練模型保存到Hdfs。
核心代碼:
#讀取原始數據
df =sqlcontext.read.json(self.app_conf["data_dir"])
rdd=df.toJSON()
#過濾出請求數據
p_rdd=rdd.filter(self.filter).cache()
#抽取數據參數
p_rdd=p_rdd.flatMap(self.extract).cache()
p_list=p_rdd.collect()
p_dict={}
#按照參數ID分(fēn)組
for p in p_list:
if p.keys()[0] not in p_dict.keys():
p_dict[p.keys()[0]]={}
p_dict[p.keys()[0]]["p_states"]=[p.values()[0]["p_state"]]
p_dict[p.keys()[0]]["p_type"]=p.values()[0]["p_type"]
p_dict[p.keys()[0]]["p_name"] = p.values()[0]["p_name"]
p_dict[p.keys()[0]]["p_states"].append(p.values()[0]["p_state"])
for key in p_dict.keys():
if len(p_dict[key]["p_states"]) self.app_conf["min_train_num"]:
p_dict.pop(key)
models=[] #訓練參數模型
for p_id in p_dict.keys():
data={}
data["p_id"]=p_id
data["p_states"]=p_dict[p_id]["p_states"]
trainer=Trainer(data)
(m,p)=trainer.get_model()
model = {}
model["p_id"] = p_id
model["p_type"]=p_dict[p_id]["p_type"]
model["p_name"] = p_dict[p_id]["p_name"]
model["model"] = pickle.dumps(m)
model["profile"] = p
models.append(model)
logging.info("[+]Trained:%s,num is %s"%(p_id,trained_num))
trained_num+=1
#保存模型參數到Hdfs,保存爲Json文件
model_df=sqlcontext.createDataFrame(models)
date=time.strftime("%Y-%m-%d_%H-%M")
path="hdfs://%s:8020%smodel%s.json"%(self.app_conf["namenode_model"],self.app_conf["model_dir"],date)
model_df.write.json(path=path)
檢測任務
Spark Streaming檢測任務實時獲取kafka流數據,抽取出數據的參數,如果參數有訓練模型,就計算參數得分(fēn),小(xiǎo)于基線輸出告警到Elasticsearch。
核心代碼:
#獲取模型參數
model_data = sqlcontext.read.json(self.app_conf["model_dir"]).collect()
model_keys=[0]*len(model_data)
for index,model_d in enumerate(model_data):
model_keys[index]=model_d["p_id"]
ssc=StreamingContext(sc,20)
model_data = ssc._sc.broadcast(model_data)
model_keys = ssc._sc.broadcast(model_keys)
zookeeper = self.app_conf["zookeeper"]
in_topic = self.app_conf["in_topic"]
in_topic_partitions = self.app_conf["in_topic_partitions"]
topic = {in_topic: in_topic_partitions}
#獲取kafka數據
dstream = KafkaUtils.createStream(ssc, zookeeper, self.app_conf["app_name"], topic)
#過濾出請求數據
dstream=dstream.filter(self.filter)
#對每條數據進行檢測
dstream.foreachRDD(
lambda rdd: rdd.foreachPartition(
lambda iter:self.detector(iter,model_data,model_keys)
)
)
ssc.start()
ssc.awaitTermination()
def detector(self, iter,model_data,model_keys):
es = ES(self.app_conf["elasticsearch"])
index_name = self.app_conf["index_name"]
type_name = self.app_conf["type_name"]
model_data=model_data.value
model_keys=model_keys.value
for record in iter:
record=json.loads(record[1])
try:
#抽取數據參數
parameters = Extractor(record).parameter
for (p_id, p_data) in parameters.items():
if p_id in model_keys:
model_d = model_data[model_keys.index(p_id)]
model = pickle.loads(model_d.model)
profile = model_d.profile
score = model.score(np.array(p_data["p_state"]))
if score
#小(xiǎo)于profile的參數數據輸出告警到es
alarm = ES.pop_null(record)
alarm["alarm_type"] = "HmmParameterAnomaly "
alarm["p_id"] = p_id
alarm["p_name"] = model_d.p_name
alarm["p_type"] = model_d.p_type
alarm["p_profile"] = profile
alarm["score"] = score
es.write_to_es(index_name, type_name, alarm)
except (UnicodeDecodeError, UnicodeEncodeError):
七、總結
所有的機器學習算法都大(dà)緻可分(fēn)爲訓練、檢測階段,基于HMM的web參數異常檢測是其中(zhōng)的典型代表,本文嘗試将機器學習算法在大(dà)數據環境下(xià)使用,所有用到的代碼都會在Github上公開(kāi)(其實數據抽取部分(fēn)并不完美,歡迎提出好的建議)。
代碼地址:https://github.com/SparkSharly/Sharly
上一(yī)篇:國家網信辦公布《互聯網新聞信息服務許可管理實施細則》
下(xià)一(yī)篇:最新“永恒之石”勒索病毒處置方案